Chapter 3 Data transformation
3.1 Understanding the Raw Data
The raw data was in a zipped format of .pgn.bz2. The unzipped .pgn file was then converted through read.py.
The result of this transformation was named “data_index.csv” each constituting 10,000,000 lines. Naturally, there were 9 files since the total count of games in the original data was 88,092,721.
Each row represented a game with columns.
This “data_index.csv” was only generated to answer the following questions.
- What items are missing in the original data?
- How many games were annotated?
The answer to the first question will be answered in the next chapter. From the data, we deduced that 7,142,630 / 88,092,721 = 8.1 % of the games were annotated compared to the 6 % claimed on the website.
3.2 Formatting the Raw Data
We decided to focus on the 7,142,630 games that were annotated.
The formatting process was done using eval.py.
This process was different from the read.py that the resulting csv(pgn_index.csv) from eval.py contained the PGN descriptions of every game played.
This process was conducted to generate a working csv dataset independent from the original data set.
The second formatting process used edit.py.
The formatting process intended to change each row to moves instead of games.
The missing data of this csv data set will be examined in the next chapter.
464,436,334 annotated moves have been played but this data set was impossible to work with due to its size. (The resulting size was 32.9 GB)
We decided to focus on the most popular time control format 600 + 0 or 10 minutes with no increment.
This time format is 16.91 % of all games.
The timecount.csv was generated through count.py.
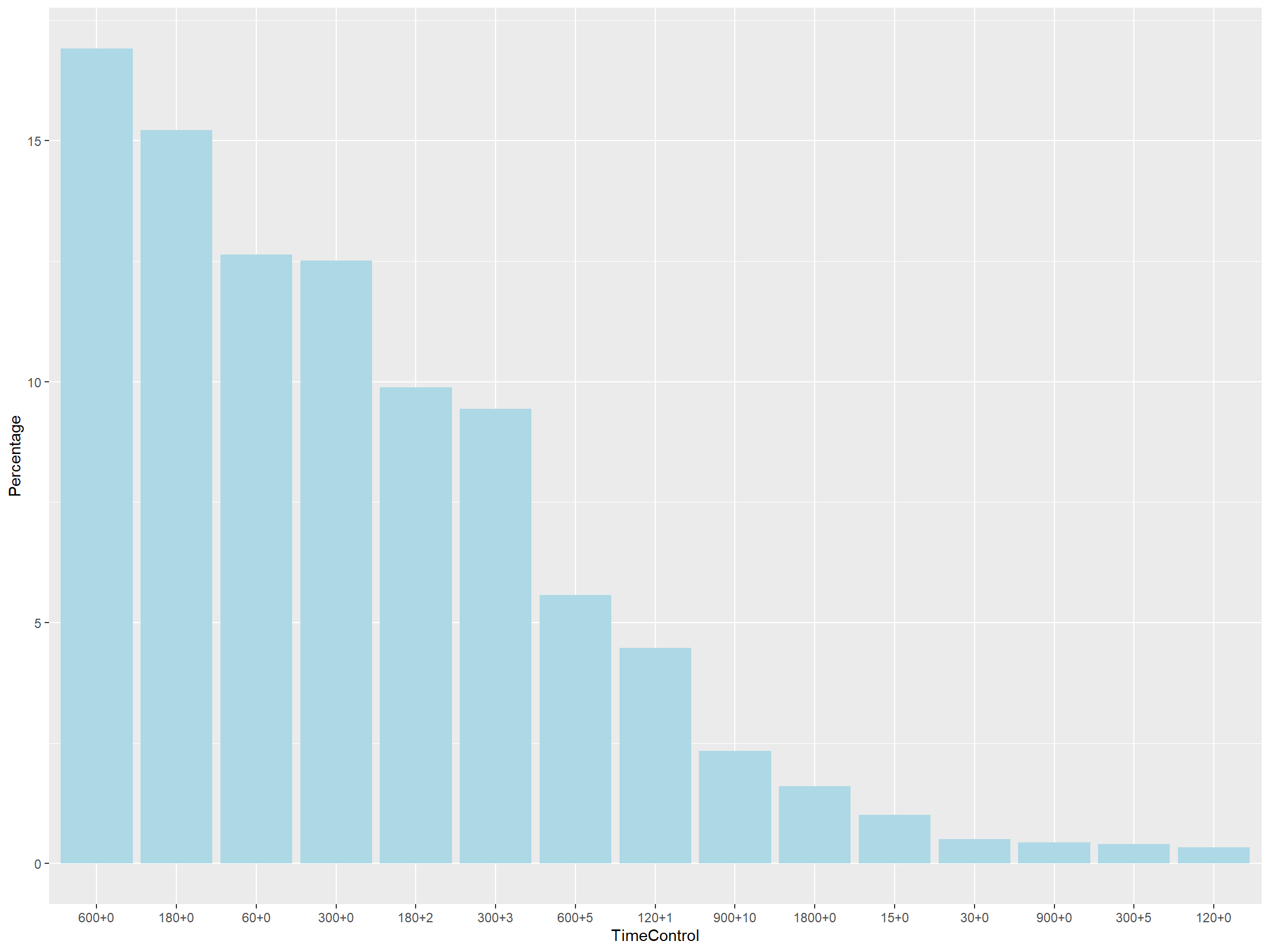
By choosing this time format, we were able to conduct a deeper analysis of the relationship between time and bad moves.
3.3 Crafting the Columns
When transforming the data to moves_index.csv, we selected and crafted columns to fit our analyses.
Since the quality of moves and time was the focus of our analysis, columns such as UTCDate, UTCTime, White, and BlackRatingDiff were removed.
Example Transformation) 1… c5 { [%clk 0:01:00] [%eval 0.00]} 2. Nf3 { [%clk 0:01:00] [%eval 0.00]} 2… d6? { [%clk 0:00:59] [%eval -1.00]}
Let’s focus on 2…d6?
- MoveNum, Color, and Move was crafted by separating the strings
2... d6to2... = bandd6?. - Type was crafted by checking whether the move included
?,?!,??,!,!?, and!!.- The purpose of creating Type was to filter the variable to understand blunders.
- Time and Eval was the %clk and %eval on the move.
- TimeSpent and EvalDiff was generated by subtracting the values.
- TimeSpent was the difference of time between moves(same color). ex) 0:00:01 between 1…c5 and 2…d6?
- EvalDiff was the difference of evaluation between turns(opposite color). ex) -1.00 between 2. Nf3 and 2…d6?
These columns were also used in 600+0.csv.
The transformation was processed using edit.py.
3.4 Focusing on 600+0 data
We can run a weighted t-test and chi-squared test on the Elo of players
Both results show that the mean of both data is the same and the data are dependent
The elocount.csv and elo600count.csv was generated through count.py.
## $test
## [1] "Two Sample Weighted T-Test (Welch)"
##
## $coefficients
## t.value df p.value
## -0.0866588 55.2709206 0.9312559
##
## $additional
## Difference Mean.x Mean.y Std. Err
## -8.984344 1647.843875 1656.828220 103.674924##
## Pearson's Chi-squared test
##
## data: df0$count and df1$count
## X-squared = 667, df = 598, p-value =
## 0.02605The following are the histogram and boxplots of the Elo distribution of all annotated games compared to 600+0 annotated games.
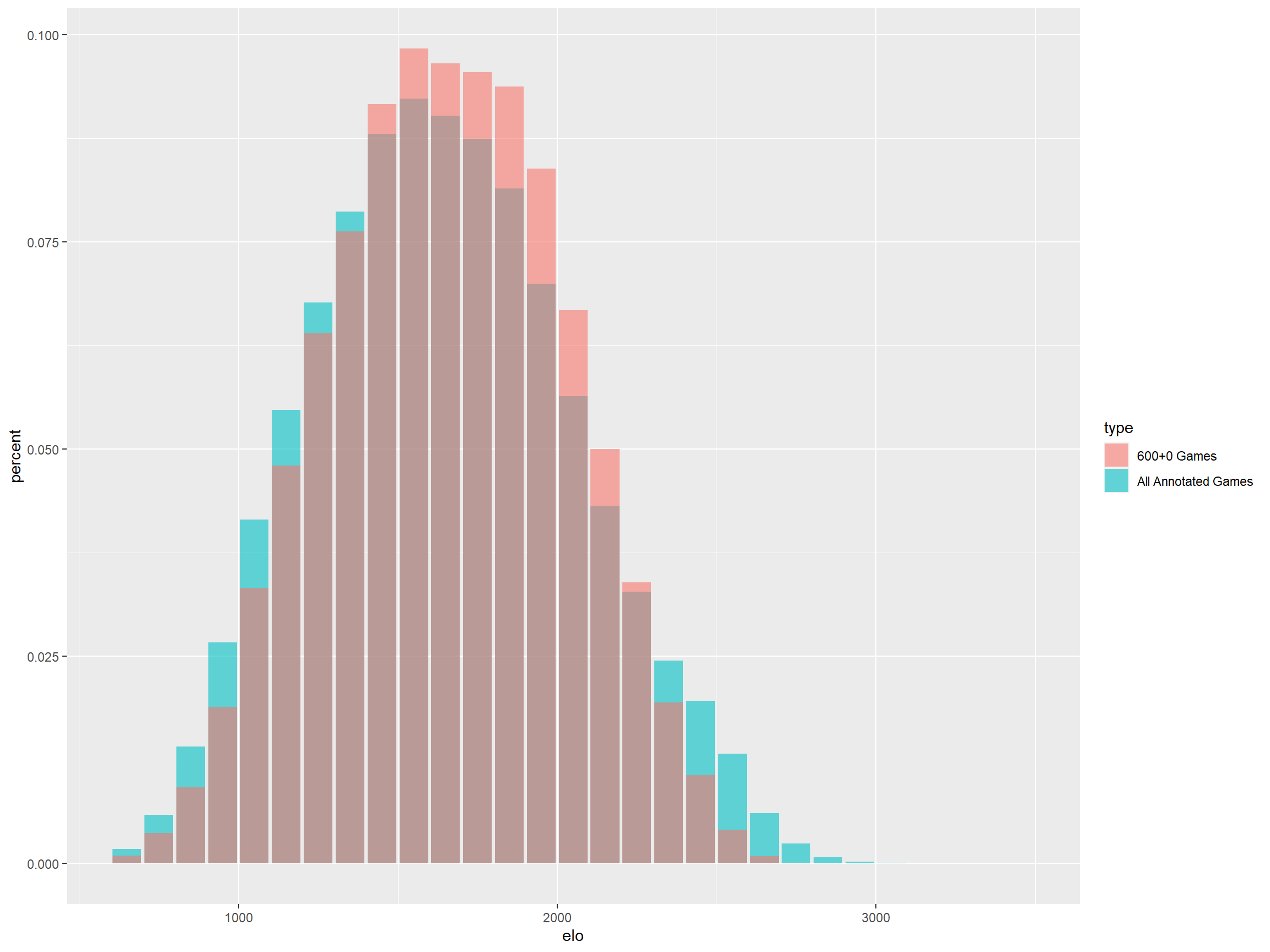
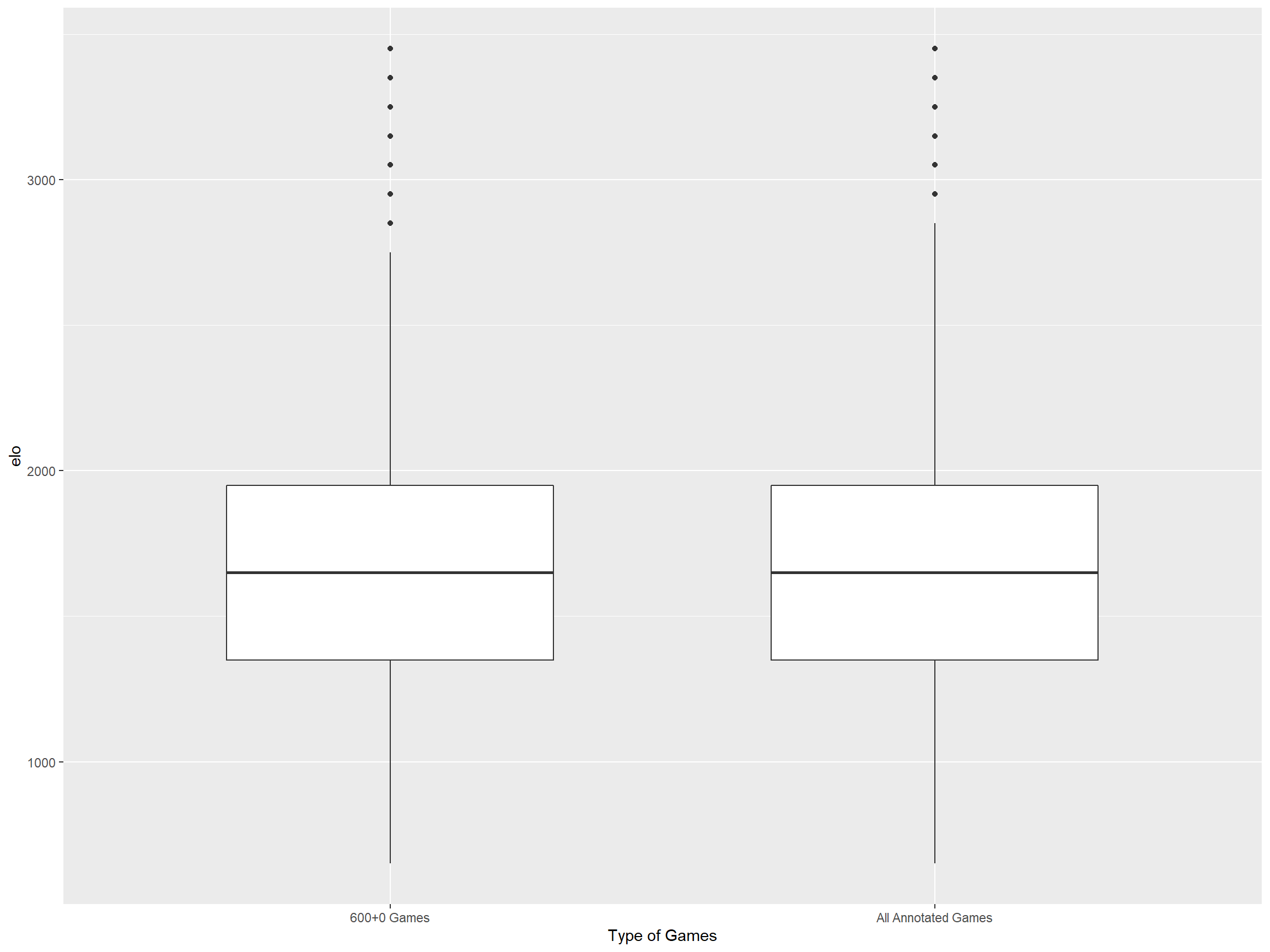
It is clear that 600+0 is a good representation of the players playing in lichess.org. The analysis will be based on the more manageable 600+0 dataset.